PageRank is an important concept in computer science and modern technology. It is important because it is the underlying algorithm that mostly dictates what more than 3 billion users who use the internet experience as they browse the world wide web.
How does PageRank work?
The first PageRank algorithm was developed by Larry Page and Sergey Brinn at Stanford in 1996. Sergey Brinn had the idea that pages on the world wide web could be ordered and ranked by analyzing the number of links that point to each page. This idea was the foundation of the imminent rise of Google as the world's most popular search engine, with now over 3.5 billion searches made by its users every day.
PageRank gives us a measure of popularity in an ever connected world of information. With an enormous degree of complexity increasing every day in the virtual space of information sharing, PageRank gives us a way to understand what is important to us as users.

The unfortunate bit of this is that PageRank itself is mostly unapproachable to anything but seasoned engineers and esteemed academics. That's why I want to make it easier for every developer around the world to make this algorithm the foundation of their innovative desires.
Distributing PageRank Jobs
It should be no surprise to regular readers of this blog that I am all about the graph. Graphs are the best abstraction of data that we have today. The concept is brilliantly easy and intuitive. Nodes represent data points and are described by meta data. Relationships connect nodes together, also described by meta data, and they enrich the information of each node relative to one another.
Neo4j Mazerunner Project
As I have been building the open source project Neo4j Mazerunner to use Apache Spark GraphX and Neo4j for big scale graph analysis, I've come to understand the need for breaking down PageRank into categories. Something I call 'Categorical PageRank'.
Categorical PageRank
This concept came to me while writing a blog post about analyzing Wikipedia. I was trying to understand why calendar year articles on Wikipedia have a distinct pattern of PageRank growth when plotted on a line graph. I introduced this data in an earlier article.

To better understand the causality it would be necessary to break each PageRank down into a set of partitions that could describe what the contributing factors were to the rise or decline of each year's PageRank. This led me to an idea. That I could build a job scheduler that would scalably distribute PageRank jobs using both Neo4j and Apache Spark. This builds on top of earlier work I've done described here.
The Design
Over the course of a weekend I was able to sketch out a design on a whiteboard and implement the functionality as a proof of concept to see whether or not it would both work and be scalable (because all things I build must be web scale).
Partitioned PageRank Diagram

The diagram above describes the property graph data model of the popular open knowledge graph, DBPedia.org. This knowledge graph is a crowdsourced community effort that extracts information from Wikipedia and organizes it as a graph data model.
The Graph Model
The graph data model consists of resources which represent Wikipedia pages and categories. The categories organize that information into a set of common groups, which forms partitions of the graph that we want to analyze. Finally, each Wikipedia page has a set of links that connect articles together.
Edge List
PageRank only requires an edge list that describes those inbound and outbound links of each page. An edge list is a simplified representation of the shape of our graph. For example, the following edge list forms a triangle where each ID represents a single node and the relationships are directed from srcId to dstId.
srcId dstId
1 2
2 3
3 1
Distributing PageRank Jobs by Category
In the diagram design I showed earlier, there are two partitions of interest that can run in graph parallel operations. Of the 4 page nodes, there are 2 nodes that belong to the blue category and 3 nodes that belong to the red category. I've colored the 1 node that belongs to both blue and red categories as purple.
While we see that the 4 page nodes have link relationships between them, the goal for me was to run the PageRank jobs on local subgraphs that described the metric for each category a node belongs to.
Versioning PageRank Metrics on Relationships
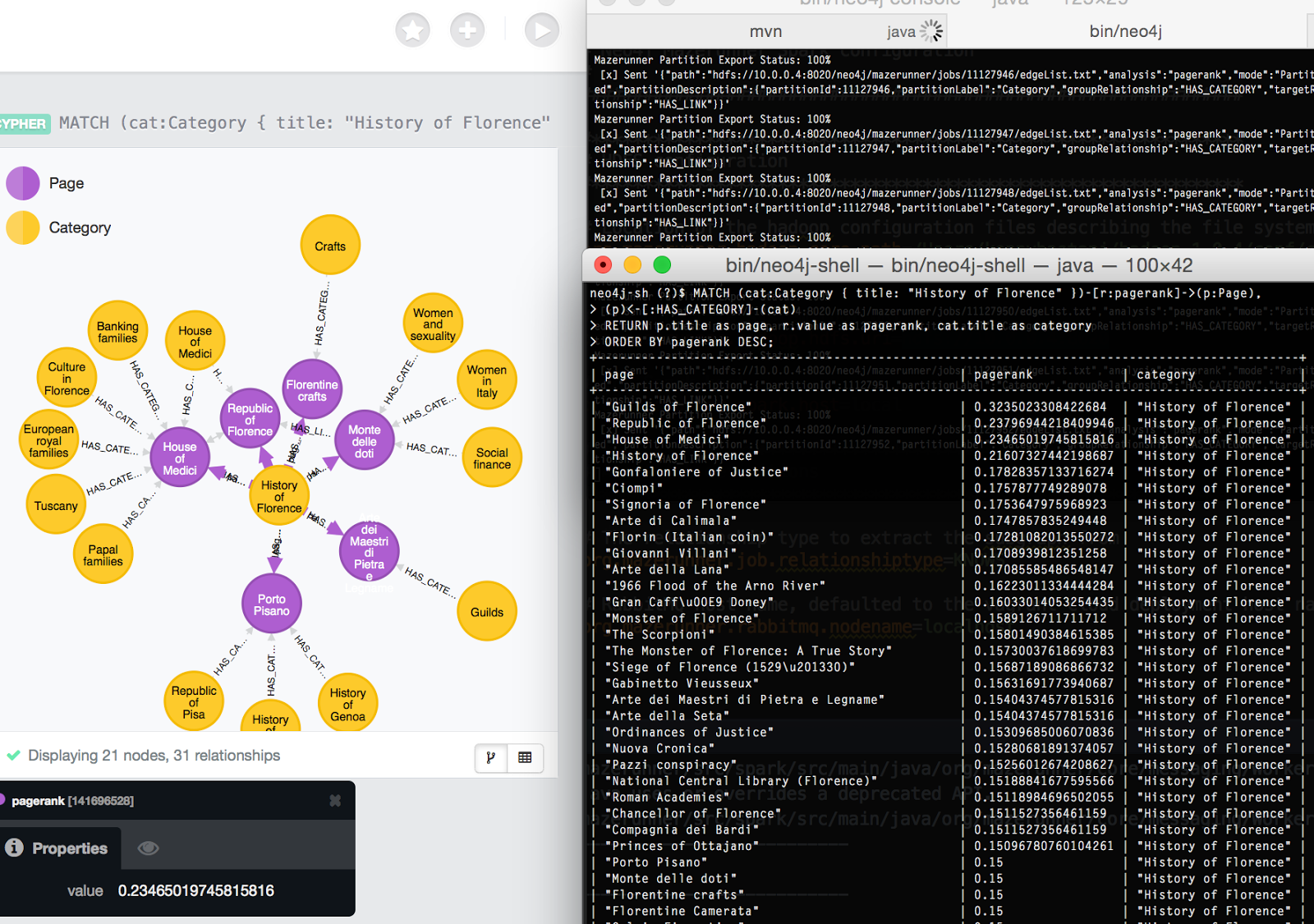
For PageRank Partition 0 in the diagram, the blue category maps to a corresponding box at the bottom and describes the results of the analysis operation.
In the previous release of Mazerunner, the PageRank metrics would be stored as a single property on each node in Neo4j. The big epiphany for me was that the Neo4j relationship entity that is displayed between category and the page nodes could have versioned metrics for each partition from the results of each PageRank analysis.
This means that multiple page nodes can have different PageRank values based on the pages's locality within the graph. This then allows you to see how a single node ranks relative to each category it belongs to.
Context-aware Knowledge Graph Search
This method turns out to provide you with a way to do context-aware relevancy ranking of pages to help refine results related to a subset of a node's categories.
The metaphor being that if Google allowed you to refine search results by categories you could better break down search queries like the following:
"Actors who won an Oscar in 2015"
We have 3 category nodes in this search result:
- Actor
- Oscar Winner
- Year:2015
Neo4j Cypher Query
After distirbuting out PageRank jobs per category, you can use a simple Neo4j Cypher query to return the search results:
MATCH (category:Category)<-[metric:HAS_CATEGORY]-(page:Page) WHERE category.title in ["Actor", "Oscar Winner", "Year:2015"] RETURN page.title, page.url, page.description, metric.pagerank as pagerank ORDER BY pagerank DESC LIMIT 10
The user ends up being able to get much more accurate search results ranked for the locality of the graph that is relevant for a query. You get both the benefit of relevance by locality and relevance by PageRank.
The prototype
The result of the proof of concept and prototype worked out great. I imported all of DBPedia into Neo4j and started up my distributed job manager for partitioning PageRank jobs.
I can scale each of the Apache Spark workers to orchestrate jobs in parallel on independent and isolated processes. HDFS is used to store the Neo4j subgraphs that are exported for each job, analyzed by Spark. When finished, each Spark worker will update the Neo4j graph with the calculated metrics.
Here is a screenshot that shows the prototype running on my laptop:
Available as open source
This feature is available as a part of the Neo4j Mazerunner open source project. You can take a look at the original story detail as an issue here: Issue 29
If you're more interested in getting it running quickly, head on over to the Neo4j Graph Analytics Docker repository and follow the setup directions to deploy it as a container to a Docker host.
This DBpedia dataset containing over 100 million nodes and relationships is also open source and available from this GitHub repository.
No comments :
Post a Comment
Be curious, I dare you.