About a year ago I read about Ray Kurzweil's "Pattern Recognition Theory of Mind", which he articulates in his book, "How to Create a Mind". I picked up the book after struggling with the idea of implementing a deep learning algorithm for parsing natural language text on Wikipedia. My goal was to discover links in volumes of text that were not already linked. I ended up developing all kinds of cool heuristics to do this, mostly by a lot of trial and error. King of these heuristics was a pretty simple algorithm at the core of the library that would find redundancies in batches of text content.
How this worked is if a phrase was mentioned repeatedly in a collection of about 50 sentences, then I could extract that phrase as a node and link it back to the pieces of content it belonged to. Every now and then you'll get a reference to another article's name, which can then be verified against Wikipedia's site index, which would provide more sentences to find repeated phrases within.
I struggled with persistency because I knew how ugly my problem was for a relational database. I created some entity-relationship models, and implemented them using Entity Framework over Microsoft SQL Server. It worked, kind of. I waited patiently to happen upon a better solution. Thankfully I did, and using a graph database I was able to take my cool little algorithms and solve my persistency problem at scale.
I struggled with persistency because I knew how ugly my problem was for a relational database. I created some entity-relationship models, and implemented them using Entity Framework over Microsoft SQL Server. It worked, kind of. I waited patiently to happen upon a better solution. Thankfully I did, and using a graph database I was able to take my cool little algorithms and solve my persistency problem at scale.
Since Neo4j allowed easy integration with graph visualization tools, I started producing some compelling images of my data. The result would yield a nice looking visualization of the contents of my Neo4j database in Gephi.

The image to the left shows article names surrounded by regular phrases that are shared by the content of many different articles on Wikipedia. The algorithm starts with a seed article, which in this case I chose the article "Dark Matter" as the seed.
As phrases are discovered within the content of the article titled "Dark Matter", they are compared to the Wikipedia site index. If a positive match is found from a phrase in one article to another's name, that article's content is then parsed using the same process.
After around 25 articles were parsed, linked, and stored as a graph, a fairly interesting image of the data emerges. Using PageRank in combination with a force directed layout, a wonderful thing appeared, a map of knowledge.
Naturally, I got pretty excited. I was reading a lot of James Gleick's books on the history of Chaos Theory and Information Theory. I started anew with a different article name, this time "Artificial Intelligence". I was feeling lucky. I started up the process, and let it be for about a day. I came back the next morning, imported the data to Gephi, did the PageRank and layout. The image below resulted.

The pattern started to emerge. Countries were situated around countries, mathematical topics next to mathematical topics, science fiction bordered topics about artificial intelligence. It was a genuine kind of discovery, the kind of thing that makes you tweet James Gleick with a presumptuous explanation that the universe is a network of information.
Since then I have been on a pursuit to learn more about the constraints of theoretical computer science. Mainly, how the heuristics I developed could be improved upon and made scalable for other kinds of unsupervised machine learning. Late last year I joined up with the company who created the database technology that allowed me to move past my graph persistency issues. This move allowed me to make graphs my life and ride the wave of an entirely new technology as it disrupts and bites off a piece of its own market.
A part of this journey has been honing my skills as a Java developer and getting into the Neo4j internals that provide the extreme performance needed to do high-volume pattern recognition at scale.
Let's assume that each node is not just data but a code block. Each block has a very specific purpose, to take an input and produce an output. Each node could therefore be thought of as a finite-state machine, which performs a bit of computation, which causes its state to change according to the result of the computation. Consider the graph diagram below.
As phrases are discovered within the content of the article titled "Dark Matter", they are compared to the Wikipedia site index. If a positive match is found from a phrase in one article to another's name, that article's content is then parsed using the same process.
After around 25 articles were parsed, linked, and stored as a graph, a fairly interesting image of the data emerges. Using PageRank in combination with a force directed layout, a wonderful thing appeared, a map of knowledge.
Naturally, I got pretty excited. I was reading a lot of James Gleick's books on the history of Chaos Theory and Information Theory. I started anew with a different article name, this time "Artificial Intelligence". I was feeling lucky. I started up the process, and let it be for about a day. I came back the next morning, imported the data to Gephi, did the PageRank and layout. The image below resulted.

The pattern started to emerge. Countries were situated around countries, mathematical topics next to mathematical topics, science fiction bordered topics about artificial intelligence. It was a genuine kind of discovery, the kind of thing that makes you tweet James Gleick with a presumptuous explanation that the universe is a network of information.
@JamesGleick You set the challenge, we answered it. The universe may be an information network that runs off entropy. http://t.co/1Hacy9F4
— Kenny Bastani (@kennybastani) January 29, 2013
I was far off point, because what I had stumbled upon didn't require any inflation or grand explanation. The image is compelling because it looks a lot like a geographical map of human knowledge. Much like Google maps, you could zoom into this graph and observe how things are connected, you could find causality at the finest granularity.Since then I have been on a pursuit to learn more about the constraints of theoretical computer science. Mainly, how the heuristics I developed could be improved upon and made scalable for other kinds of unsupervised machine learning. Late last year I joined up with the company who created the database technology that allowed me to move past my graph persistency issues. This move allowed me to make graphs my life and ride the wave of an entirely new technology as it disrupts and bites off a piece of its own market.
A part of this journey has been honing my skills as a Java developer and getting into the Neo4j internals that provide the extreme performance needed to do high-volume pattern recognition at scale.
Let's assume that each node is not just data but a code block. Each block has a very specific purpose, to take an input and produce an output. Each node could therefore be thought of as a finite-state machine, which performs a bit of computation, which causes its state to change according to the result of the computation. Consider the graph diagram below.
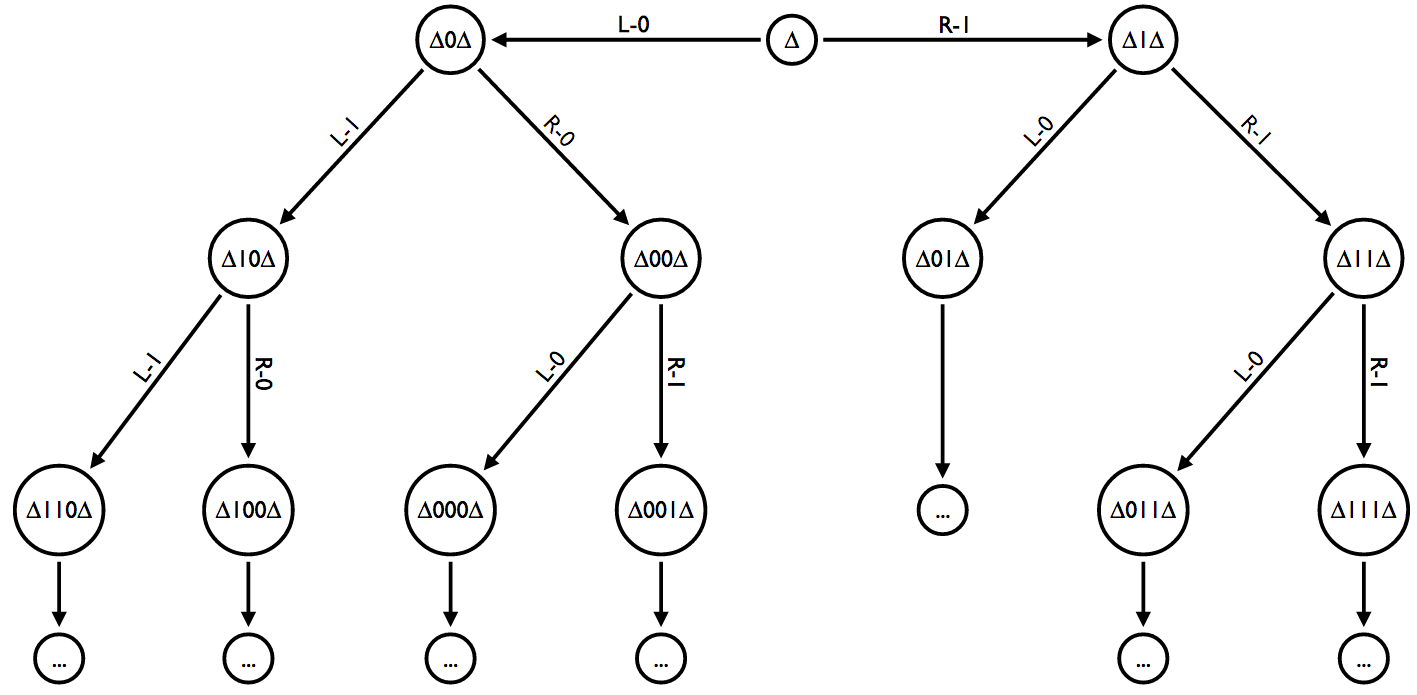 |
| Hierarchical Pattern Recognition Graph |
The ∆ symbol represents something similar to a qubit, which could be 1 or 0 or a superposition of both. I realize the metaphor of a qubit may be confusing, so to simplify this, a ∆ is a wildcard match on an input represented as a bit, being 1 or 0. As a stream of bits are processed, new nodes are created that have some statistical probability of being selected based on a history of matches on training data. As the number of matches of some threshold θ is surpassed, the leaf node changes states and produces two or more leaf nodes, depending on the number of ∆ in the pattern template of the node.
The new leaf nodes inherit the template of the parent node, but replace each ∆ with the bit selected based on the statistical probability measured over all previous matches for the parent. New ∆ wildcards encapsulate the new templates that are produced. This natural selection of patterns produces an algorithmic data structure from input data. Labels can be connected to nodes from labeled training data, like faces in photos or images of text.
This is largely inspired by Ray Kurzweil's PRTM and Jeff Hawkin's Hierarchical Temporal Memory. Both approaches teeter on the cusp of some kind of deep learning.
Quote from the Wikipedia article about Deep Learning:
Vote on Hacker News
The new leaf nodes inherit the template of the parent node, but replace each ∆ with the bit selected based on the statistical probability measured over all previous matches for the parent. New ∆ wildcards encapsulate the new templates that are produced. This natural selection of patterns produces an algorithmic data structure from input data. Labels can be connected to nodes from labeled training data, like faces in photos or images of text.
This is largely inspired by Ray Kurzweil's PRTM and Jeff Hawkin's Hierarchical Temporal Memory. Both approaches teeter on the cusp of some kind of deep learning.
Quote from the Wikipedia article about Deep Learning:
...These models share the interesting property that various proposed learning dynamics in the brain (e.g., a wave of neurotrophic growth factor) conspire to support the self-organization of just the sort of inter-related neural networks utilized in the later, purely computational deep learning models, and which appear to be analogous to one way of understanding the neocortex of the brain as a hierarchy of filters where each layer captures some of the information in the operating environment, and then passes the remainder, as well as modified base signal, to other layers further up the hierarchy.That's all for now. Stay tuned for updates.
No comments :
Post a Comment
Be curious, I dare you.