For most users that use the Neo4j browser, this is an ideal experience for learning and designing great graph data models for querying. For applications that require a deeper control over how graphs are stored and queried, the native Java API provides a great deal of benefits. When using the Java API you gain a degree of freedom to tell Neo4j how to query your data.
The Cypher query language, with an innovative SQL-like syntax for graphs, is a declarative query language. That means you tell Neo4j what you want and not how to get it. When you run a Cypher query you are expressing to the graph database what you want from it. In turn, Neo4j maintains a compiler that translates that query into an execution plan that describes a set of data operations, arranged such that data is obtained from the graph and processed sequentially through each operation until a result is generated for the user.
The Cypher query language, with an innovative SQL-like syntax for graphs, is a declarative query language. That means you tell Neo4j what you want and not how to get it. When you run a Cypher query you are expressing to the graph database what you want from it. In turn, Neo4j maintains a compiler that translates that query into an execution plan that describes a set of data operations, arranged such that data is obtained from the graph and processed sequentially through each operation until a result is generated for the user.
What does an execution plan look like?
The typical approach for interacting with Neo4j involves sending a Cypher query and parameters in a POST request to the Neo4j database server. We call the frameworks or libraries that manage wrappers around the REST API methods of Neo4j from an arbitrary programming language a "driver". These drivers transport queries and results over the network and Neo4j further translates the declarative syntax of Cypher into an execution plan.
Using the Neo4j web-based console, we can get the results of each query in the detailed query results.
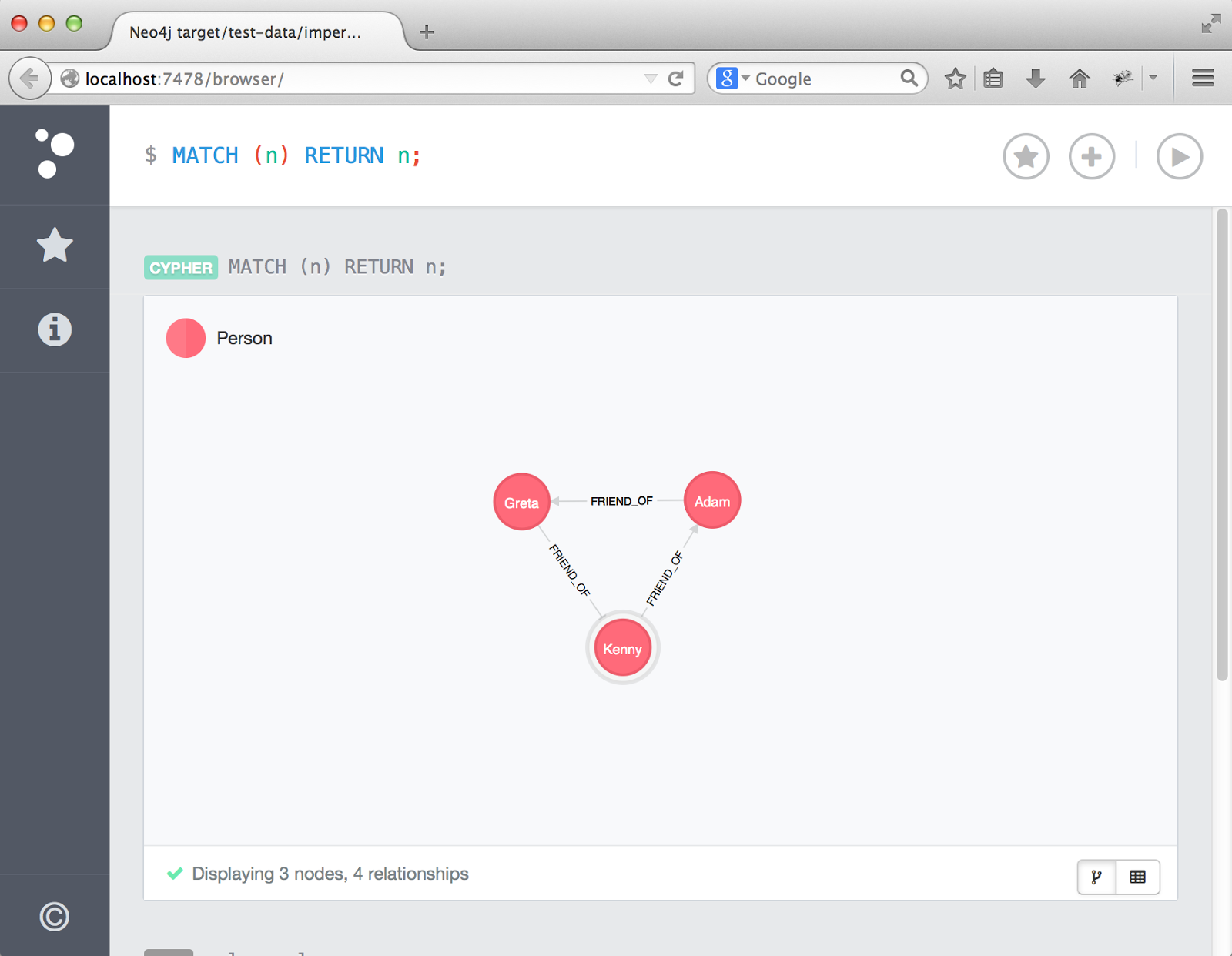
I've setup a sample graph with 3 people: Kenny, Adam, and Greta. These 3 people are friends on a social network.
If you run an "All Nodes" query in the console above:
// All nodes query MATCH (n) RETURN n
You will be able to see the detailed results by clicking on the "Result Details" button, shown in the screenshot below.

Detailed Query Results
As the execution plan states, the Cypher query has been translated to the AllNodes operation.Query Results
+-----------------------+ | n | +-----------------------+ | Node[6]{name:"Kenny"} | | Node[7]{name:"Adam"} | | Node[8]{name:"Greta"} | +-----------------------+ 3 rows 6 msExecution Plan
AllNodes +----------+------+--------+-------------+-------+ | Operator | Rows | DbHits | Identifiers | Other | +----------+------+--------+-------------+-------+ | AllNodes | 3 | 4 | n, n | | +----------+------+--------+-------------+-------+
Now if we run a slightly more complex Cypher query, the execution plan shows the piping of operations.
// Find Kenny's friends
MATCH (kenny:Person {name:"Kenny"})-[:FRIEND_OF]-(friends)
RETURN friends
Detailed Query Results
Query Results
+-----------------------+ | friends | +-----------------------+ | Node[1]{name:"Adam"} | | Node[2]{name:"Greta"} | +-----------------------+ 2 rows 14 msExecution Plan
ColumnFilter | +Filter | +TraversalMatcher +------------------+------+--------+-------------+--------------------------------------------+ | Operator | Rows | DbHits | Identifiers | Other | +------------------+------+--------+-------------+--------------------------------------------+ | ColumnFilter | 2 | 0 | | keep columns friends | | Filter | 2 | 12 | | Property(kenny,name(0)) == { AUTOSTRING0} | | TraversalMatcher | 6 | 13 | | friends, UNNAMED37, friends | +------------------+------+--------+-------------+--------------------------------------------+
The execution plan for the query shows 3 operators: ColumnFilter, Filter, and TraversalMatcher. The ColumnFilter operation receives a row of data from the Filter operation and processes it by keeping only the identifier "friends", which is in the RETURN statement. The Filter operation also receives rows of data from its preceding operation, the TraversalMatcher, and applies a predicate to decide whether to pass that data row along to the next operation (the ColumnFilter) or to discard it. In the case of our query, the predicate is to filter nodes by applying the criteria for the identifier "kenny" with the property "name" that equals AUTOSTRING0, which will resolve to the token "Kenny" when the plan is executed. Finally the TraversalMatcher doesn't receive any rows of data, due to being the first operation, but generates new rows of data by searching the graph for the pattern specified in the MATCH clause.
So you can see that the execution plan, as constructed from the Cypher query, operates bottom up. Patterns are found in the TraversalMatcher (a total of 6 rows), and then passed through the Filter, which only allows 2 through, and finally to the ColumnFilter, which only keeps the "friends" column specified in the RETURN clause.
Knowing how the data is generated, filtered, and processed is tremendously helpful for understanding how to optimize queries for the best performance. The compiler does what it can to generate the most optimal plan. It is constantly being made smarter with each release, yet its still extremely relevant for us developers to understand what the result is — and to consider how we can adjust the query we're asking to obtain a more optimal result.
Vote on Hacker News
So you can see that the execution plan, as constructed from the Cypher query, operates bottom up. Patterns are found in the TraversalMatcher (a total of 6 rows), and then passed through the Filter, which only allows 2 through, and finally to the ColumnFilter, which only keeps the "friends" column specified in the RETURN clause.
Knowing how the data is generated, filtered, and processed is tremendously helpful for understanding how to optimize queries for the best performance. The compiler does what it can to generate the most optimal plan. It is constantly being made smarter with each release, yet its still extremely relevant for us developers to understand what the result is — and to consider how we can adjust the query we're asking to obtain a more optimal result.
No comments :
Post a Comment
Be curious, I dare you.